CASE STUDY
X
AI CHARACTER CONSISTENCY

Client & Objective
The client is a children’s animation studio aiming to develop a new character from scratch as the basis for future audiovisual content. The project began with a single reference image, intended to be transformed into a consistent, production-ready visual identity.
Rather than simply recreating the character, the objective was to build it entirely using AI—testing the capabilities and limitations of generative tools while designing a stable, repeatable system capable of preserving identity across multiple environments, emotions, and narrative scenarios.
Base Character Creation
Since the client provided only a single reference image, the base character was developed through an iterative process using ChatGPT’s reference-based image generation. This approach proved especially effective for preserving proportions, facial structure, age, and overall character balance when starting from minimal visual input.
Through multiple rounds of careful and detailed prompting, the model was guided to respect the original proportions, soft facial features, and stylized child anatomy. This phase focused exclusively on stabilizing the character’s visual identity, deliberately avoiding complex environments, actions, or narrative elements.
The result was a consistent base character that served as the visual foundation for all subsequent workflows, including LoRA training, controlled prompting, and scalable environment exploration.
LoRA Training
Once the base character was defined, the best generations were selected and lightly refined to correct minor inconsistencies in proportions, facial features, and outfit details. These curated images were then used to train two custom LoRAs: one on SDXL for high-quality still imagery, and another on WAN 2.1 for video generation.
During training, regular sample images were generated at different steps to monitor character stability, proportion accuracy, and identity preservation across new environments. The images shown below represent these training-time samples, illustrating how consistency progressively improved as the LoRA converged.
Custom Workflows for Image and Video
With the LoRAs trained, custom generation workflows were built for both image and video production.
For still imagery, a custom Stable Diffusion workflow was designed, combining the character LoRA with ControlNet Depth to reinforce proportions, silhouette, and structural consistency across poses and environments.
For motion, a dedicated WAN-based video workflow was developed, integrating the character LoRA to maintain identity throughout sequences while allowing controlled variation and movement. These workflows were delivered to the studio as stable, repeatable production tools, enabling consistent character generation without manual prompt tuning for every output.
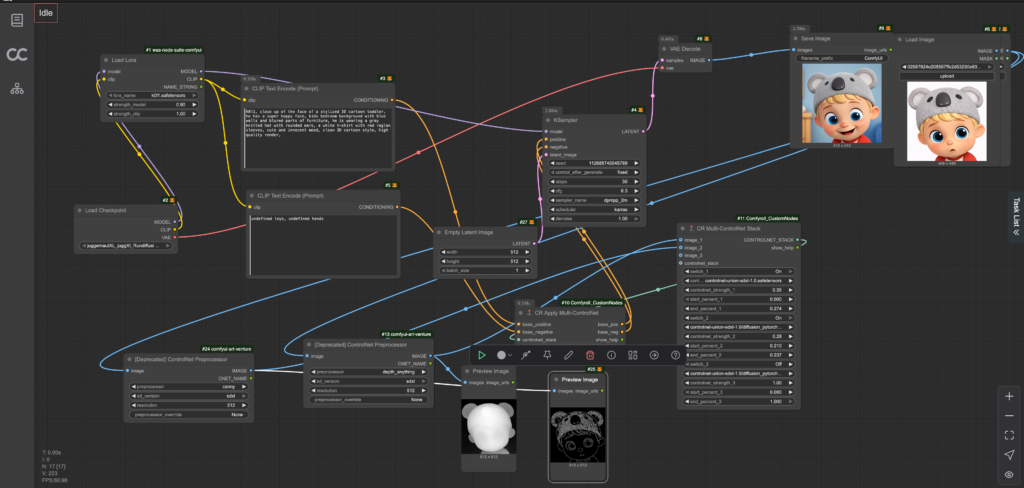
The visuals shown below represent final outputs generated using the stabilized image and video workflows. These examples demonstrate how the character maintains consistent proportions, identity, and visual language across different environments and scenarios, while remaining flexible enough for creative variation and narrative use.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}